Chuyện character encoding
#Encoding
#Encoding Standard
Về cơ bản máy tính chỉ làm việc với các con số. Nên các ký tự muốn máy tính hiểu được thì chúng phải ở dạng số. Vì vậy các Encoding Standard (chuẩn Encoding) sinh ra để quy định số thứ tự cho mỗi ký tự. Mỗi encoding quy định một danh sách ký tự mà nó hỗ trợ. Có khá nhiều encoding standard: ASCII, ISO-8859-1, JIS X 0208, Unicode...
#Character Encoding
Character Encoding là việc convert số thứ tự của ký tự (trong chuẩn Encoding mà nó đang tuân theo) sang binary. Mỗi encoding sẽ có một tập quy tắc encode/decode tùy theo chuẩn của nó.
#UTF-8
Ví dụ với encoding phổ biến mà chúng ta (mình) hay dùng: UTF-8 - là một encoding tuân theo chuẩn Unicode.
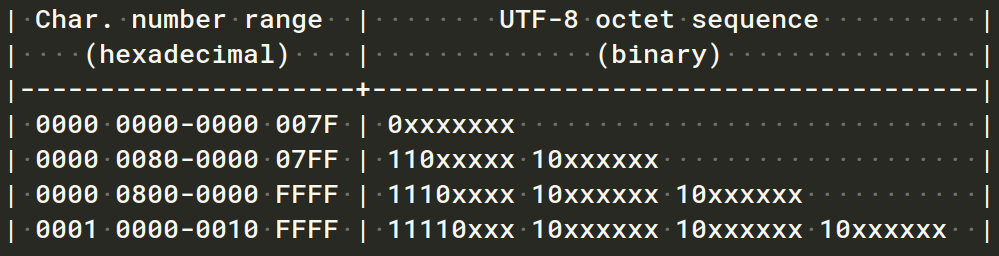
Với ký tự trong khoảng 0 - U+007F trong Unicode table, UTF-8 sử dụng 8bit để encode, với bit đầu = 0 để đánh dấu, các bit còn lại để xác định vị trí của ký tự trong bảng Unicode. Nghĩa là khi decode, gặp byte nào có bit đầu tiên = 0 thì có nghĩa là byte đó lưu một trong các ký tự trong khoảng 0 - U+007F.
Các ký tự còn lại được sử dụng nhiều hơn 8 bit:
- Ký tự trong khoảng
U+0080 - U+07FF, sử dụng 2 byte để encode. Byte đầu có dạng110xxxxxvà ngay sau đó là 1 byte dạng10xxxxxx - Ký tự trong khoảng
U+0800 - U+FFFFcó dạng:1110xxxx 10xxxxxx 10xxxxxx - Ký tự trong khoảng
U+10000 - U+10FFFFcó dạng:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Loại trừ các bit có tác dụng đánh dấu, các bit còn lại sẽ là vị trí của ký tự trong bảng Unicode.
Ví dụ:
1. 01100001 có dạng 0xxxxxxx, loại bỏ bit đánh dấu (bit 0 đầu tiên) ta được số bit còn lại là 1100001
Chuyển đổi sang decimal hoặc hex: 11000012 = 6116 =9710. Sau đó tìm trong Unicode table thì ta được ký tự a ở vị trí số 97 (hay 61 trong hệ hexadecimal)

2. 11100011 10000010 10110101 có dạng 1110xxxx 10xxxxxx 10xxxxxx, lược bỏ các bit có tác dụng đánh dấu:

Kết quả: 00110000101101012 = 30B516 = 1246910. Tra trong bảng Unicode ta được

Với ví dụ trên thì đó là bước decode từ binary ➜ index. Còn để encode, thì chỉ cần xác định index của ký tự thuộc khoảng nào, chọn sequence tương ứng, convert index ➜ binary rồi fill các bit vào.
Với quy luật này thì nếu có thêm một lượng lớn ký tự nữa, UTF-8 vẫn tiếp tục đáp ứng được bằng cách thêm sequence mới (ví dụ 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx).
#Có nhiều encoding
Mặc dù Unicode về sau đã có gần như có đầy đủ các ký tự cho tất cả các ngôn ngữ, emoji, symbols... Tuy nhiên không phải ở đâu cũng dùng UTF-8. Vì với một số ngôn ngữ, ký tự của họ trong Unicode nằm ở index lớn, dẫn đến việc lưu trữ bằng UTF-8 sẽ gây lãng phí bộ nhớ (hoặc băng thông khi truyền dữ liệu). Ví dụ cùng ký tự モ trong tiếng Nhật, nếu dùng encoding Shift_Jis chỉ mất 1 byte (11010011) để lưu trữ còn UTF-8 mất đến tận 3 byte (11101111 10111110 10010011). Vì thế nếu dữ liệu đó chỉ lưu ở một tập ngôn ngữ cố định và bài toán về độ lớn của dữ liệu là quan trọng thì ta nên chọn encoding một cách hợp lý.
Việc có nhiều encoding tuân theo các chuẩn encoding khác nhau dẫn đến chúng ta hay gặp một vài lỗi như:
- Mở file text mà toàn ký tự linh tinh (unreadable): có thể đó không phải là file text, hoặc có thể bạn đang mở file text đó ở một encoding khác với encoding mà file đó đã được lưu.
- Gửi text đúng lên backend nhưng data trong db lại sai: có thể dữ liệu binary gửi lên ở một dạng encoding khác, nhưng lưu vào db lại ở encoding khác.
Việc implement một encoding cũng không phải đơn giản. Encoding không chỉ đáp ứng quy luật để encode/decode các ký tự cho đúng với Encoding standard, mà nó còn phải đáp ứng các giải thuật tìm kiếm (như Boyer–Moore, Bitap...).
#Kết
Bên trên chỉ là những thứ cơ bản mà mình hiểu về Character encoding. Còn khá nhiều điều thú vị như convert giữa 2 encoding, mối quan hệ với font chữ, chi tiết về các giải thuật tìm kiếm, cũng như Regex hoạt động thế nào... Hy vọng sẽ tìm hiểu được trong tương lai không xa để chia sẻ thêm  .
.